Method
As shown in the Figure above, the whole process consists of three steps, 1) Extracting trajectories, 2) Learning convolutional feature maps, and 3) Constructing Trajectory-Pooled Deep-Convolutional Descriptors.
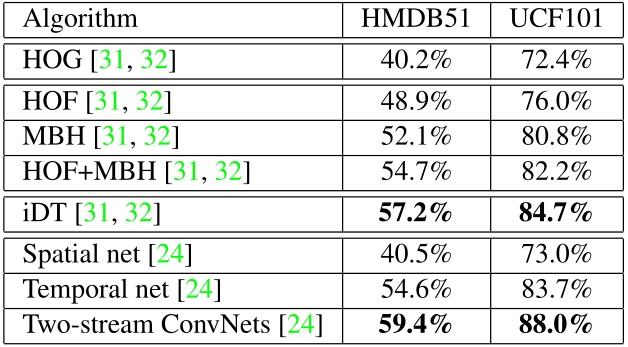
Extracting trajectories: We choose to use Improved Trajectories due its good performance on action recognition. However, we only track on a single scale to speed up the process of trajectory extraction.
Learning convolutional maps: We exploit two-stream ConvNets to learn discriminative feature maps from both RGB images and optical flow fields. Meanwhile, we construct the multi-scale pyramid representation of both modalities and thus obtain the multi-scale convolutional feature maps.
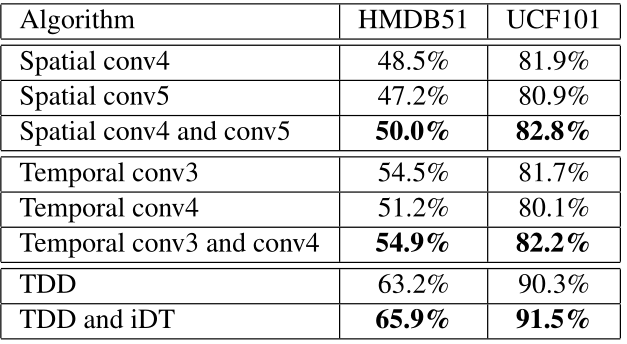
Constructing TDD: After the extraction of trajectories and convolutional feature maps, we perform trajectory-constrained pooling to aggregate feature maps into effective descriptors, called TDD. To enhance the discriminative capacity of TDD, we propose two kinds of normalization method: (i) spatio-temporal normalization and (ii) channel normalization.
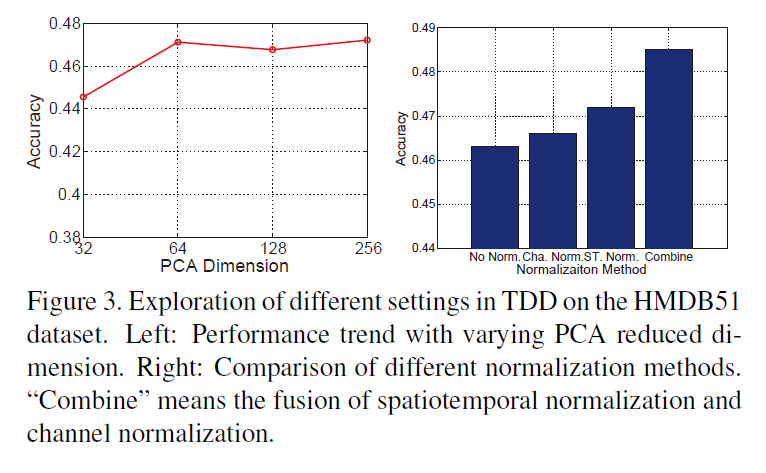
For video representation, we resort resort to Fisher vector encoding to transform the TDDs of a video clip into a high-dimensional representation. Before Fisher vector encoding, we conduct PCA pre-processing to de-correlate the dimension of TDD and reduce it to 64-dimension.